作者:周秉誼 / 趨勢科技 技術經理
深度學習(Deep Learning)在各種不同應用上強大的效能令人驚嘆,讓許多人想要了解深度學習的原理,也想要進一步把深度學習應用在自己感興趣的領域。而要了解深度學習的技法,除了學習理論的部份,對初學者來說,用一個簡單的實際例子來快速上手,也是很有效率的途徑。
深度學習最常見的應用,包括影像識別、語音辨識、自然語言處理等,甚至推薦系統、生醫資訊等,各種和生活相關的領域都可以看到深度學習的應用。而其中影像辨識又是應用最廣泛、最容易上手的例子,只要掌握其中的精髓就可以快速的套用到其他以深度學習為核心的框架,如深度強化學習(Deep Reinforcement Learning)。因此本文將以深度學習在影像辨識上的實例,帶大家了解深度學習、打造自己的深度學習模型。
影像辨識一直是人們最希望用人工智慧(Artificial Intelligence)和機器學習(Machine Learning)來幫忙處理的問題。自從網際網路和各式行動裝置普及之後,每天都有超過一百萬TB的數位資料產生,其中有一大部份是數位影像資料。大量的數位影像資料如果經過適當的自動化處理、抽取出其中的資訊,就能成為貼心的服務、發揮出數位資訊驚人的妙用。從基本的手寫文字辨識、物件識別、人臉辨識,到自動化圖像描述(Image Captioning)、無人駕駛車(Self-Driving Car),還有最新的馬賽克還原技術,都是深度學習和影像辨識整合後的應用。
資料集
然而深度學習除了需要大量的資料,更需要大量有標記(Label)的資料,才能在訓練過程(Training)讓深度學習的模型(model)學習到判別的關鍵。比如手寫數字辨識就需要把每個手寫影像標記上代表的數字、人臉辨識就需要標示出影像上臉部的位置、物件識別就需要標示每個圖片中有什麼物品。這些整理成特定格式、標示好的資料就是資料集(Dataset),對機器學習和深度學習都是非常重要的。
MNIST資料庫(Mixed National Institute of Standards and Technology database)是一個歷史悠久的手寫數字(handwritten digits)資料集,許多研究人員會使用MNIST資料來比較不同機器學習演算法的效果好壞,因此也有很多前人研究的做法可以供我們參考和學習。MNIST手寫數字資料集可以在LeCun教授的網站(http://yann.lecun.com/exdb/mnist/)上取得,其中共有70,000個手寫數字的影像,每一個都是28x28大小的灰階(grey level)影像,也有分別標示為0到9的數字。不過資料被儲存成比較特別的IDX檔案格式,下載之後可以先用簡單的python程式轉存成CSV格式方便後續資料讀取。本文後續會使用MNIST測試資料集(testing set)中的10,000筆資料來進行訓練和辨別。
圖一:MNIST手寫數字資料集範例

圖二:python程式碼: MNIST資料轉換為CSV格式
建構深度學習模型
要建構一個深度學習模型,最簡單的方式就是使用python的Keras套件。Keras內建了非常多常用的深度學習的類神經網路元件,包括卷積層(convolutional layer)、遞歸層(Recurrent layer)等等,而底層計算又是直接使用TensorFlow或Theano,所以對開發人員來說是非常方便的實驗平台。本文將會使用Keras來建構深度學習模型。
要使用Keras的第一步,就是要把資料整理成Keras所需要的資料格式。在手寫數字辨識中,影像資料的部份就是存放成一個巨大的四維numpy陣列(array),四個維度分別是每一筆資料、影像灰階值、影像長、影像寬,陣列中的每一個數值都在0到1之間的浮點數(float),代表了不同影像中各個位置正規化(normalization)後0到255的灰階值。每個影像分別是那一個數字的標記資訊就存放在另一個陣列中。所以程式的第一個部份,就是把CSV格式的手寫數字影像資料讀取出來,存成兩個陣列X跟Y。
再來就要建構深度學習的類神經網路(Artificial neural network)架構。在Keras中可以直接使用keras.models模組提供的Sequential類別來建構網路架構,再將keras.layers模組提供的各個類神經網路層(layer)填進Sequential物件的網路架構,就可以完成類神經網路架構的建置。建置完成後,只要呼叫compiler函式進行編譯,再接著呼叫fit函式並傳入mini batch的數量等參數,就可以開始訓練了。 第一個模型將使用到一個卷積層、一個池化層(Pooling layer)、一個內部的完全連接層(Fully connected layer)、和一個以softmax輸出結果的完全連接層。只要依次呼叫Sequential物件的add函式將Convolution2D、MaxPooling2D、Dense等類神經網路層加入就可以了。設定之後再呼叫compile函式設定loss function為categorical_crossentropy、並使用adadelta最佳化工具。
為了有資料進行模型訓練跟結果驗證(verify),我們將10,000筆資料分成兩個部份,前8,000筆做為訓練資料,後2,000筆當成驗證用的資料。把訓練資料X_train、Y_train和驗證資料X_test、Y_test餵進fit函式,經過一些時間,就可以得到第一個深度學習模型的結果了。透過Keras中model物件提供的to_json函式及save_weights函式,我們可以把訓練好的深度學習模型儲存到檔案中。之後要使用時就可以用model_from_json函式及load_weights函式將訓練完成的模型直接載入使用。
改善深度模型的效果
除了Keras提供的數值外,也可以使用scikit learn套件提供的分析工具來仔細觀察深度學習模型的效果。sklearn.metrics模組裡的confusion_matrix函式可以統計每一個數字類別實際上被分類的結果,classification_report函式可以進一步計算出每個數字類別的精確率(Precision)及召回率(Recall)。這兩個函式的結果可以幫助我們分析每一個數字的難易度和效果,進一步了解目前深度學習模型的盲點,才能找出改善的方式。
要怎麼讓結果更好呢?改良深度學習的類神經網路架構是一個可行的做法。但類神經網路架構中可以調整的地方實在太多了,每一個網路層的神經元數量、卷積層及池化層的大小、各網路層的數量及排列方式、活化函數的選擇、最佳化工具的學習率(Learning rate)等等,都是可以調整的。想要在這麼多參數選項中找到一個最好的排列組合,難度是非常高的,也不容易有系統化的做法。想要改良類神經網路架構的一個簡單方式是,參考前人在類似問題的研究成果,拿現成的架構先用看看。
第二個模型參考了Keras的範例,使用到兩個卷積層、一個池化層(Pooling layer)、一個內部的完全連接層(Fully connected layer)、和一個以softmax輸出結果的完全連接層。依照先前的方式呼叫Sequential物件的add函式,依序將Convolution2D、MaxPooling2D、Dense等類神經網路層加入,並設定最佳化工具後,就可以把資料餵給fit函式進行訓練和驗證了。第二版的模型的效果比第一版模型更好,準確率(Accuracy)提升了將近1.5%,可見深度學習的網路架構對結果的影響是非常大的。
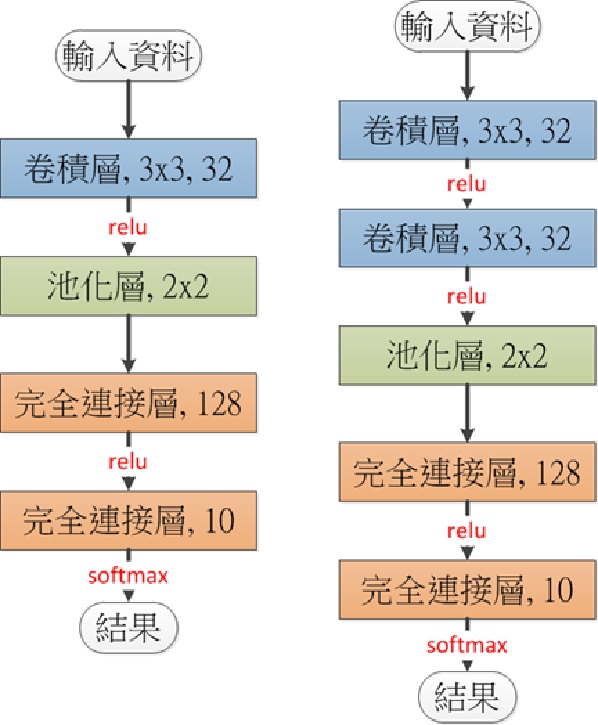
圖三:深度學習網路架構(第一版及第二版)
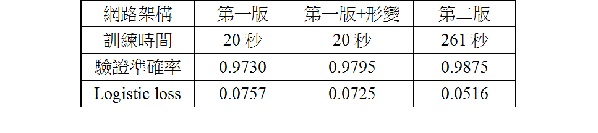
圖四:深度學習網路架構比較(第一版及第二版)
深度學習模型的效果除了跟類神經網路架構有關,還跟訓練的次數(epoch)及訓練資料的數量等各種不同的參數有關。以訓練次數為例,如果把不同訓練次數的結果畫成一張學習曲線(Learning Curve)圖,就可以協助我們判斷模型是否達到最佳表現、是否要增加訓練的次數。以第一版的模型為例,在固定8,000筆訓練資料的情況下,最佳的訓練次數大約在7到10次之間,第一版模型的效果就能達到上限準確率約0.98,訓練次數增加反而可能帶來過度擬合(overfitting)的情況,反而會使模型的效果變差。
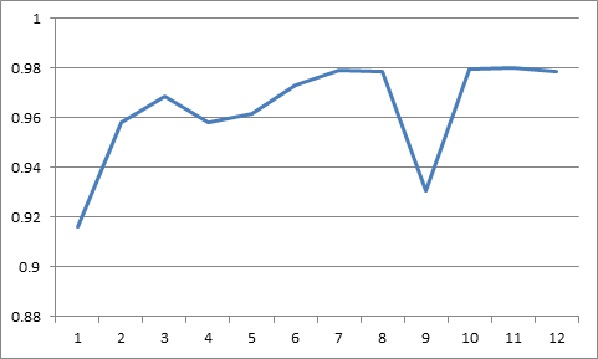
圖五:訓練次數的學習曲線圖(第一版)
形變:增加資料的方式
訓練資料的數量是另一個深度學習成功與否的關鍵。而針對影像資料的特性,有一個很有效的增加資料的方式,就是把影像做些微的形變(Distortion),如小角度的旋轉(rotation)、小距離水平或垂直的平移(shift),對某些影像資料還可以做水平或垂直的鏡像(flip)。大部份的影像資料不會因為小範圍的形變,而改變影像本身的本質或內涵,增加形變後的影像資料反而更能讓深度學習模型學習到更關鍵的特性,使得模型的效果更好。
想要產生形變的影像資料,除了使用PIL(python image library)套件提供的rotate、resize等函式自行對影像操作之外,Keras套件的keras.preprocessing.image模組中也提供了ImageDataGenerator類別,可以自動產生形變後的訓練資料,形變的類型和程度都可以透過參數的設定來修改。以第一版的模型為例,使用形變後的訓練資料,可以再讓模型的準確率提升0.6%。
結語
雖然深度學習的功能非常強大,但想要改進深度學習的效果常常比傳統的機器學習模型更難。因為網路架構中可以調整的設定和參數太多了,想要在這麼多參數選項中找到一個最好的排列組合,目前沒有系統化的做法。另外深度學習網路就像黑盒子(black box),人們不容易理解模型中各網路層的內涵,就無法做出有效的調整。TensorFlow中的TensorBoard工具提供了一個視覺化的介面,除了可以呈視高維資料的分佈,還能方便人們了解各個參數的影響。
影像的分析和處理跟人們生活中的行為習習相關,各種電腦視覺的應用也常讓人驚嘆。而深度學習的出現更是讓電腦對影像類的資料有更深一層的認識,因此處理影像資料的深度學習架構應用的層面非常廣泛。比如讓電腦學會自己玩遊戲的深度強化學習中,就會使用處理影像的深度學習模型來模擬策略函數(Policy function)或價值函數(Value function)。無人駕駛車也會使用物件識別的模型來分辨路上的物品是行人還是車子。所以由影像辨識的實作來認識深度學習,是非常有效率的學習方式,方便之後跟其他的深度學習應用接軌。

圖六:讀取CSV資料檔轉為numpy陣列

圖七:Keras網路建構和訓練流程

圖八:MNIST手寫數字辨識執行流程

圖九:Keras形變工具ImageDataGenerator範例