作者:鄭彥宏 / 臺灣大學計算機及資訊網路中心程式設計組幹事
在系統開發上來說,以往需要申請者上傳紙本資料如證件、佐證資料等含有文字及特定內容資料時,最大的困擾往往在無法於資料上傳時即判別內容是否符合所需。本文透過以Google Cloud Vision API作圖像識別應用,系統開發者無須具備機器學習(Machine Learning)等背景來建立特定分析模型(model),即可依據不同的回應需求分析出圖像內容並加以運用,趕緊一起來動手實作吧!。
前言
拜現代AI(Artificial Intelligence)人工智慧科技的演進,曾幾何時,遙想當年我們在家裡按著紅白機手把上的按鈕,絞盡腦汁想要贏過電視螢幕上那狡猾的電腦角色時,是否也曾幻想那小小的遊戲卡匣裡究竟是躲著哪位幽靈棋手如此技術高端?一直到近年由Google DeepMind團隊開發的AlphaGo在眾人的關注下,以三比零在人類世界中擊敗頂尖九段棋士,這才讓世人開始討論人工智慧的好與壞。暫且不論人工智慧在使用失當會有何等影響,試想此一科技應用在現下你我的日常生活中帶來多少便利性?出門可遠端遙控家電、監控的智慧家庭(Smart Home),手機上諸如Siri、Google Assistant或小愛同學等幾乎無所不知的語音助理,甚於半個世紀前又或是二、三十年前無法想像的科技正在我們的生活中日趨月異;在系統開發上來說,以往需要申請者上傳紙本資料如證件、佐證資料等含有文字及特定內容資料時,往往最大的困擾在無法於資料上傳時即判別內容是否符合所需(上傳風景照當證件https://www.ptt.cc/bbs/Bank_Service/M.1555601183.A.581.html),必須在管理者逐筆核對下才能判別並要求補件;透過本篇文章說明以Google Cloud Vision API作圖像識別應用,系統開發者無須具備機器學習(Machine Learning)等背景來建立特定分析模型(model),即可依據不同的回應需求分析出圖像內容並加以運用,趕緊一起依下述步驟動手做做看吧!
Step.1申請成為GCP(Google Cloud Platform)帳號
正所謂「工欲善其事,必先利其器」,在訪問Google各項API前必須先設置好相關的權限設定,詳細的步驟可參考https://theonetechnologies.com/blog/post/how-to-get-google-app-client-id-and-client-secret或是參照Google官方說明文件設置即可,不在此贅述;完成後將取得一組API Key如圖1作使用;值得注意的是,目前GCP帳號開啟後有一年的試用期限,並提供300美元的使用額度,各項API的免費使用次數也有上限,詳細的說明可以參考主頁說明https://cloud.google.com/vision/。


圖1:Google Cloud Platform API Key
Step.2 造訪Google Cloud Vision API
由於Google Cloud Vision API是一REST API,係透過HTTP POST的方式作訪問互動,其發送請求(request)的位址如圖2,此處的Api_Key即為上一步驟所得到的API Key。


圖2:Google Cloud Vision API Request Url
其POST的資料內容則如圖3,資料格式(format)是由一圖像來源及辨識參數所組成的JSON format file,各項內容說明如下:
content:目前Vision API提供3種圖片來源,包含base64-encoded image string、Google Cloud Storage URI及a publicly-accessible HTTP or HTTPS URL;考量實際系統開發使用上的狀況,在此我們呼叫javascript函式readFile()透過FileReader()將圖像讀取後轉換為base64字串作使用,如圖4。
type:請求的圖像識別種類,如印刷文字識別(TEXT_DETECTION)、臉部偵測(FACE_DETECTION)、地標偵測(LANDMARK_DETECTION)及商業識別偵測(LOGO_DETECTION)等,詳細說明可見Features說明https://cloud.google.com/vision/docs/features。
maxResults:回應的結果數,設置為0將接收所有偵測結果;若解析出的結果超過1個以上,則可透過此參數設定返回的數量,以減少後續解析內容的不必要。
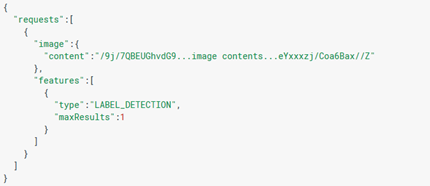

圖3:Vision API Request Body(資料來源:https://cloud.google.com/vision/docs/request#json_request_format)
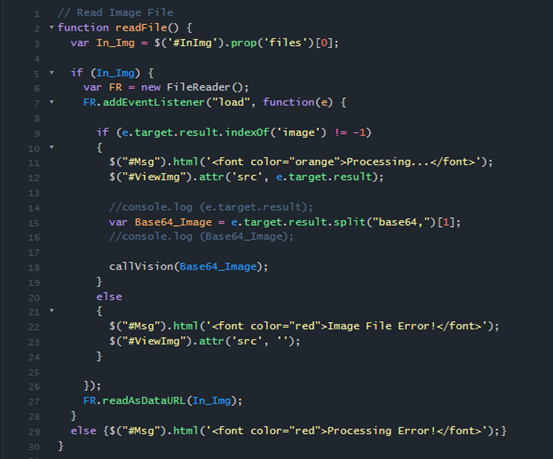
圖4:javascript Function readFile()
最後,建構一函式callVision(),讀入圖片經轉換後的base64字串,並透過jQuery ajax以POST的方式將訪問的請求送出如圖5,將返回的結果(同樣為JSON format)在console上作檢視,整個實作的核心就大致完成了;完整的Source Code及Demo Image可以在https://jsfiddle.net/ehroimc/ax6bfp8g/及https://www.space.ntu.edu.tw/navigate/s/8694A36B0D294DEEAE0B270B4919DAA5QQY找到,僅需替換API Key即可,緊接著就趕緊來看看實際使用的狀況吧!
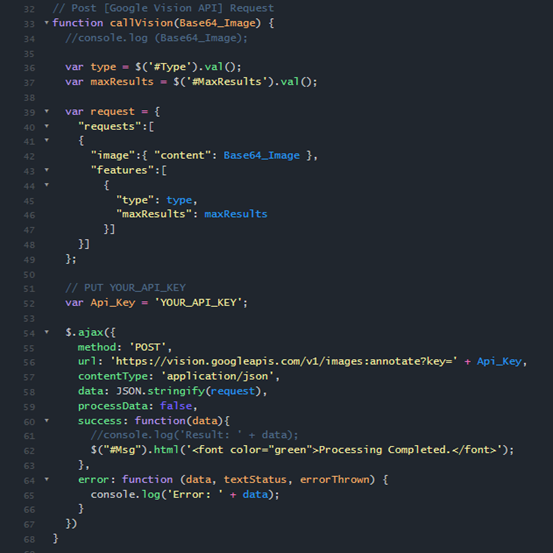
圖5:jQuery ajax Function
Step.3 解析回應內容
以本篇實作所提供的Source Code分別以不同的圖像作各種識別類型的回應分別如下:
印刷文字辨識(TEXT_DETECTION):可辨識出圖像內所含的印刷(非手寫)文字,且能自動辨別語言,如圖6。

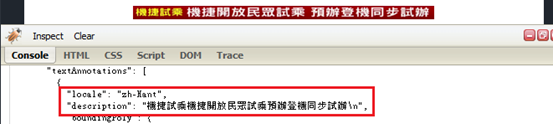
圖6:Type TEXT_DETECTION response
手寫文字辨識(DOCUMENT_TEXT_DETECTION):不同於印刷文字,手寫文字辨識上的難度及準確率都更為複雜,如圖7。

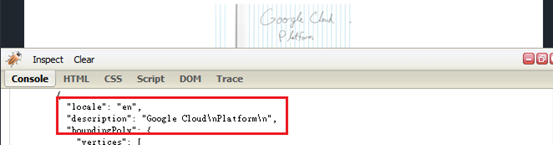
圖7:Type TEXT_DETECTION response
商業識別偵測(LOGO_DETECTION):辨識圖像中熱門的商標圖示,並且估算準確性權重值(score),如圖8。

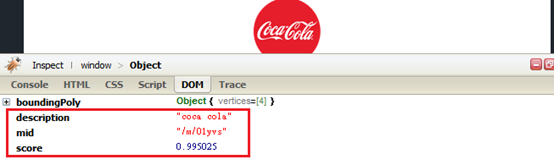
圖8:Type LOGO_DETECTION response
地標偵測(LANDMARK_DETECTION):辨識圖像中著名的地標、自然景觀及建築物等,回應的內容除以四點座標標示出位於圖像中的位置外,更提供該地標的經緯座標供其他後續開發應用,如圖9。

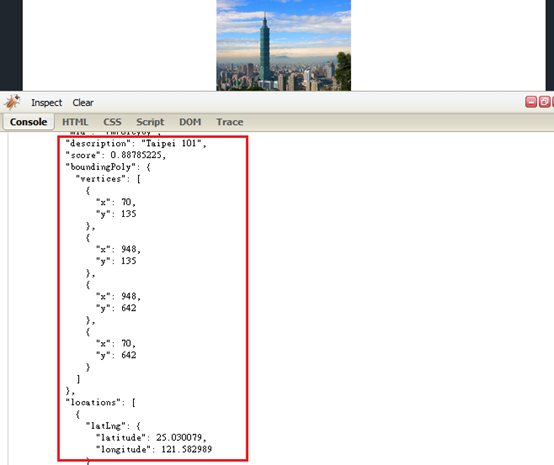
圖9:Type LANDMARK_DETECTION response
除了以上所作幾種較常會使用到的識別外,另外還包含煽情露骨內容偵測(SAFE_SEARCH_DETECTION)及臉部偵測(FACE_DETECTION)等,在本次的實作中也都能以不同的圖像發送取得回應,各類型的回應結構也能在官方的說明頁https://cloud.google.com/vision/docs/how-to內找到對照,在後續的應用上,依照不同的識別類型作回應解析,大致上已應能滿足多數的使用需求了。
結語
在本文開頭提到,以往在圖像識別應用開發上,譬如車牌、證件資料亦或人臉辨識系統,往往需要耗費大量的專業人力以及投注龐大的研發經費與設備等,在現今網路雲端技術的幫助下,已經能站在巨人的肩膀上以更便捷的方式達到目的;除了本文所介紹的Google Cloud Vision API外,類似的OCR(Optical Character Recognition)在Google Project上還能找到「Tesseract」此HP輾轉交由Google維護的開源代碼(open source)專案,相關連結請參照參考資料,有興趣可以再另外實作看看喔!
參考資料
Google Cloud Vision API:https://cloud.google.com/vision/
Google Cloud Vision API Documentation:https://cloud.google.com/vision/docs/
Tesseract OCR:https://opensource.google.com/projects/tesseract
Tesseract.js:https://github.com/naptha/tesseract.js