作者:林淑芬 / 臺灣大學計算機及資訊網路中心教學研究組程式設計師
資料探勘對於學術界與實務界而言,是一門兼具問題、理論與方法的學科。在這裡我們即嘗試以不同資料探勘的理論為經,演算方法為緯,藉著不同領域的個案實例,以IBM/SPSS Modeler系統的實際操作,來說明資料探勘模型所能提供問題的解決方法。
前言
資料探勘是一門結合統計學與資訊科學相關理論的方法學,藉由各種功能模式的導入與實踐,挖掘出隱藏在資料中的有用資訊。我們也可以說資料探勘對於學術界與實務界而言,是一門兼具問題、理論與方法的學科。本文以IBM/SPSS Modeler系統的實際操作,說明資料探勘模型所能提供問題的解決方法。資料探勘的主要模型可大致分為以下三大類:
1. 分類(Classification):分類模型使用一個或多個輸入的值來預測一個或多個輸出目標的值。分類模型可幫助組織預測已知的結果,例如顧客是否購買、流失。
2. 集群(Clustering):集群模型將數據劃分為具有類似輸入的記錄。在不知道特定結果的情況下,例如想將潛在用戶分成幾個相似的子群組,在客戶群中識別利益群體時,集群模型非常很有用。
3. 關聯(Association):關聯模型可找出數據中的模式,其中一個或多個實體與一個或多個其他實體相關聯。關聯模型在預測多個結果時非常有用,例如,購買了產品X 的顧客也購買了產品Y和Z。
在這裡我們將分別以這三大類型舉例,簡易說明如何以SPSS Modeler系統建立模型和分析的實際操作步驟,讓使用者可以輕鬆快速地了解資料探勘是如何幫助我們分析巨量資料,提供我們潛藏在資料中有用 的資訊。
一. 分類範例: 乳腺癌醫學診斷應用
決策樹演算法可說是在資料探勘的領域中最常被使用的演算法之一。Ross Quinlan在1986年提出ID3演算法後,因其無法處理連續屬性的問題且不適用在處理大的資料集,因此1993又發表C5.0前身C4.5,直到現在所使用的C5.0決策樹演算法。C5.0演算法的結果可產生決策樹及規則集兩種模型,並且依最大資訊增益的欄位來切割樣本,並重複進行切割直到樣本子集不能再被分割?止。
本範例檔wdbc.txt是乳腺癌(Breast Cancer Diagnostic)的診斷資料,取自美國加州大學歐文分校的機械學習資料庫http://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+%28Diagnostic%29。這是Wisconsin大學臨床研究中心於1995年蒐集569例乳腺癌症的病患實際診斷資料,診斷的方式是對於可疑的乳腺腫塊使用細針穿刺的技術 (Fine Needle Aspirate, FNA)蒐集數位化圖像並加以計算,欄位共32項,說明如下:
第1欄:識別號碼(ID number):識別號碼
第2欄:診斷結果(Diagnosis):惡性(M = malignant)、良性(B = benign)
第3-32欄:這30項資料全部都是計算每一個細胞核的真實資料測量值,包含以下的內容:半徑(radius)、紋理(texture)、周長(perimeter)、範圍(area)、平滑度(smoothness)、緊密度(compactness)、凹陷部分的程度(concavity)、凹陷部分的數量(concave points) 、對稱度(symmetry) 、碎型維度(fractal dimension)等。
資料探勘的過程如下:
首先設定【變數檔案】節點,選擇檔案wdbc.txt,然後再設定【類型】節點,按「讀取值」,由於【C5.0】模型節點需要至少一個「輸入」的輸入欄位,以及一個或以上的「目標」欄位,且目標欄位必須是類別型態變數。所以我們將診斷結果(Diagnosis)欄位的角色設成「目標」,其他欄位的角色全設成「輸入」。

圖1 欄位的角色設定
然後以【C5.0】節點建立分類模型,選擇產生決策樹輸出,執行後產生模型金磚(nugget)如下:

圖2 建立分類模型,選擇產生決策樹輸出
打開模型金磚,可以查看模型內容。左側視窗是決策樹,顯示出規則(括號內是符合此規則的筆數及信賴度)、右側視窗是預測變數重要性,C28和C24是兩個最重要的變數值,畫面如下:

圖3 模型產生的規則和預測變數重要性
亦可選擇由上至下或由左至右決策樹的不同檢視方式:

圖4 決策樹的檢視
最後輸出矩陣和正確率分析結果,我們可看到利用C5.0模型分類,原本診斷為惡性,而使用C5.0模型,也被分類為惡性的有206筆;原本診斷為良性,而使用C5.0模型,也被分類為良性的有356筆,正確率高達98.77%,只有7筆分類錯誤。
二. 集群範例:動物園的動物分群應用
集群分析就是將異質的群體區隔,分成一些同質性高的子群組或集群,不需要事先定義好該如何分類,也不需要訓練組資料,而是靠資料自身的相似性集群在一起,最常使用在市場區隔的應用上。
K平均法(K-means)是最受使用者歡迎以及最佳集群分析法之一,K-Means演算法是麥昆(J. B. MacQueen)於1967年正式發表,由於原理簡單、計算快速,屬於前設式的集群演算法,也就是必須先設定集群的數量,然後根據該設定找出最佳的集群結構,因此【K-Means】節點不需「目標」欄位。分群需注意要確保Cluster具代表性,原則上5-10% 為最低門檻,也要注意總體Cluster的數量,過多欄位會產生過多的Cluster,造成分析上的困難,建議2-12個。
本範例的動物分群資料,取材自美國加州大學歐文分校的機械學習資料庫http://archive.ics.uci.edu/ml/datasets/Zoo,這個動物園的動物資料集包含了101筆的紀錄,將動物分為7群,資料當中包含了如下所列的18個欄位:
1. 動物的名字(animal name):唯一值
2. 是否具有毛髮(hair):Boolean值
3. 身體是否有羽毛(feathers):Boolean值
4. 是否會下蛋(eggs):Boolean值
5. 是否會產奶(milk):Boolean值
6. 是否在空中(airborne):Boolean值
7. 是否在水中(aquatic):Boolean值
8. 是否會獵食(predator):Boolean值
9. 是否有牙齒(toothed):Boolean值
10. 是否有骨幹(backbone):Boolean值
11. 是否會呼吸(breathes):Boolean值
12. 是否有毒(venomous):Boolean值
13. 是否有鰭(fins):Boolean值
14. 腿的數量(legs):{0,2,4,5,6,8}集合的數字
15. 是否有尾巴(tail):Boolean值
16. 是否被馴化(domestic):Boolean值
17. 是否屬貓科(catsize):Boolean值
18. 類型(type):在1到7範圍內的整數值,表示將動物分為7群
先設定【變數檔案】節點,選擇檔案zoo.txt,然後再設定【類型】節點,按「讀取值」,將類型type欄位的角色設成「無」,其他欄位的角色全設成「輸入」。
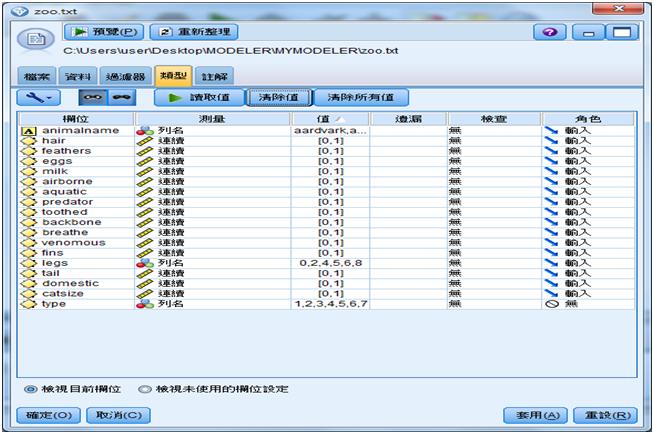
圖5 欄位的角色設定
然後連結【K-Means】節點,準備建立模型。在模型的設定中,我們已經知道動物的分群是分為七類,所以可以使用這個數字作為分群的標準。

圖6 叢集模型的設定
執行後可產生模型金磚(nugget),點選模型內容,可以查看模型建立集群的狀態。左側視窗選擇模型摘要、右側視窗選擇集群大小,顯示畫面如下:

圖7 叢集模型的內容
按下預覽鈕可看到如下結果,最後兩個欄位是在建立模型之後才會出現的內容。「$KM-K-Means」表示模型分群後的預測結果,「$KMD-K-Means」則表示該筆紀錄與其集群中心的距離。

圖8 每筆紀錄與其集群中心的距離
最後我們可連結【矩陣】節點,查看使用K-Means分群後的結果與實際分群的差異。列的位置是正確的分群結果,欄的位置是模型的分群結果。矩陣表中對於原資料中所分的群,type-1、type-2、type-4、type-5、type-6的分群結果與模型結果相吻合,但在type-3、type-7的類型則有少許的偏差。

圖9 模型分群後的結果與實際分群的差異
三. 關聯範例:超市購物關聯分析
在資料探勘的領域之中,關聯性法則(association rule)是最常被使用的方法,其法則大致是『if 前項antecedent(s) then後項consequent(s) 』的概念。關聯性法則在於找出資料庫中資料間彼此的關聯性。而在關聯性法則之使用中,Apriori是最為著名且廣泛運用的演算法。
本範例的超市購物資料,檔案的欄位說明如下:購買產品分為Ready made、Frozen Food、Alcohol、Fresh Vegetables、Milk、Bakery goods、Fresh meat、Toiletries、Snacks、Tinned Goods等10個類別,有買則資料值設為1,沒買則資料值設為0,另外還包括一些個人基本資料,諸如性別、年齡等。
首先設定【變數檔案】節點並設定【類型】節點,將購買產品欄位的測量改成「旗標」,角色設成「兩者」,其餘設為「無」。「兩者」表示資料會進入Apriori模型節點分析,此欄位的資料可以在關聯規則的前項也可在後項中出現。

圖10 欄位的角色設定
然後連結【Ariori】節點,準備建立模型,並設定最小規則支援、最小規則信賴度等細節,當門檻值過高而無法生成模型時,使用者須適度調整門檻值。

圖11 關聯模型的設定
執行後產生4個關聯規則,可以查看詳細的規則內容。排序的準則有支援度(Support)、信賴度(Confidence)、規則支援%(Rule Support)、後項(Consequent)、提昇(Lift)以及可部署性(Deployability)等方式,使用者可依需求選擇。

圖12 關聯模型產生的關聯規則
以第一個關聯規則為例解釋如下:全部總共786筆資料,買Milk和Frozen Food的人是85筆,買Bakery goods的人是337筆,買Milk和Frozen Food而且買Bakery goods的人是71筆,買Milk和Frozen Food但不買Bakery goods的人是14筆。所以後項是指Bakery goods;前項是指Milk和Frozen Food;實例是85,即為符合前項的筆數;支援度為10.814% = 85/786,是指購買前項產品的客戶佔全部客戶的比例;信賴度為83.529 %= 71/85,是指購買前項產品的客戶中也買後項產品的比例;規則支援%(即支援度x信賴度)是9.033 %= 10.814% x 83.529% 或= 71 / 786,指購買前項產品也買後項產品的客戶佔全部客戶的比例;提昇是1.948,即等於(71/85)/ (337/786)或 = 83.529% / 42.875%,指購買後項產品佔購買前項產品的比例除以購買後項產品佔全部客戶的比例;可部署性是1.781 %=14/786,即為購買前項產品但不買後項產品的人佔全部客戶的比例。
若降低最小規則信賴度從80%至75%,則可產生26個關聯規則,提供我們參考顧客購買物品的關聯性。

圖13 更多的關聯規則